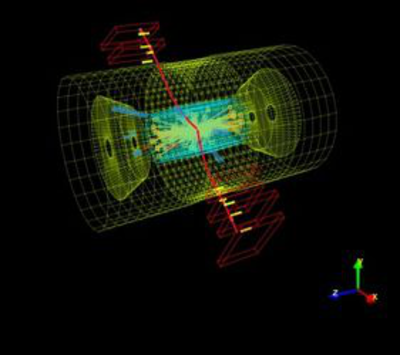
El CERN ha puesto a disposición del público parte de la información relativa al experimento CMS (Compact Muon Solenoid) que tiene lugar en el LHC (Large Hadron Collider o Gran Colisionador de Hadrones). A través del portal Open Data de la organización se pueden consultar y descargar los datos, que se han separado en dos selecciones principales: los destinados a la comunidad investigadora y los orientados a fines educativos.
En los picos de rendimiento tienen lugar 1,000 millones de colisiones de protones cada segundo en el detector CMS del LHC. El CMS ha recogido 64 petabytes (cantidad equivalente a más de 64,000 TB) de información sobre estas colisiones hasta el momento. Y parte de esta información es la que se ha hecho pública.
Los datos fueron recogidos en el año 2010 y su puesta a disposición del público forma parte del compromiso del experimento CMS (uno de los que se llevan a cabo en el LHC), que ha establecido sacar a la luz la información tres años después de haberla obtenido y una vez los investigadores la hubieron estudiado a conciencia. Héctor García Morales, físico de la Royal Holloway University of London, apunta que se han publicado dos tipos de datos: los primarios y los derivados. "Los primarios serían los datos más o menos tal cual salen del detector mientras que en los derivados solamente parte de la información se mantiene, aquella información que cumple una serie de requisitos. El resto de colaboraciones (ATLAS, ALICE y LHCb) por el momento solamente han colgado los datos derivados. La idea es que las diferentes colaboraciones vayan colgando los datos primarios unos tres años después de haber sido obtenidos y después de haber sido analizados por las propias colaboraciones. Es decir, cada año irán saliendo los primarios de hace 3 años", comenta García Morales.
Toda la información se ha publicado bajo licencia Creative Commons CC0, que convierte estos recursos en dominio público. Además, los datos y el software cuentan con un identificador DOI, que permite citarlos en artículos científicos y localizarlos fácilmente en internet.
El CERN también facilita el acceso a software de código abierto para leer y analizar la información disponible, así como la documentación necesaria y las instrucciones para facilitar su instalación y uso. Uno de los deseos expresados desde el CERN es que esta información se pueda volver a analizar décadas después. No en vano, hacerla pública es una forma de conservarla. Todos estos datos se unen a los papers ya publicados por el centro de investigación.
Solo se han hecho públicos los datos que actualmente ya no están siendo objeto de análisis. Liberarlos es una manera de hacer que sigan siendo aprovechables aunque el CERN no esté trabajando con ellos.
La clasificación de los datos en cuatro niveles
EL CERN ha dividido la información en cuatro niveles, con diferente accesibilidad y target para cada uno de ellos. El nivel 1 comprende cualquier información incluida en las publicaciones sobre el experimento CMS, así como cualquier anotación numérica que las complemente. El nivel 2 está orientado al sector educativo. Consta de ejemplos para que docentes y estudiantes se familiaricen con la información. Se trata de una primera toma de contacto, para que los alumnos tomen conciencia de cómo funciona el análisis en física, pero las herramientas no ofrecen la capacidad de profundizar demasiado.
Visualización de datos con el programa educativo
El nivel 3 es el destinado a científicos especializados y está compuesto por los datos que los investigadores dentro del experimento CMS utilizaban para sus análisis. Se puede acceder a representaciones significativas de la información, simulaciones y la documentación que ayuda a comprender el resto de recursos, así como el software para analizar los datos. En cuanto al nivel 4, consiste en toda la información en bruto sobre las colisiones, pero sin identificar los elementos, y no se hará pública. Aparte de esta clasificación, todos los artículos y los resultados de los análisis están recopilados en un sitio web para su consulta gratuita.
Datos moldeados con fines educativos
Además de la información sobre el experimento CMS, el CERN también ha liberado la referente a otros experimentos del LHC, como son ALICE, ATLAS y LHCb. La información referente a cada uno de ellos ha sido preparada para su uso por parte del sector educativo, con herramientas de visualización.
La información está en internet, accesible para cualquiera. Pero lo cierto es que es necesario contar con conocimientos avanzados de física para dar cierto uso a los datos. De hecho, los científicos del CERN trabajan en grupos y se apoyan los unos en los otros durante meses y años para, a veces, llevar a cabo un único análisis. Además, hay que entender el software que se usa, lo que conlleva un proceso de aprendizaje para alguien que no está habituado a utilizarlo.
Por eso el CERN ha lanzado un programa piloto destinado a la educación. Está parcialmente financiado por el Ministerio de Educación y Cultura de Finlandia. Se compartirán datos del CMS con escuelas de Finlandia y esta información formará parte de una plataforma general proporcionada por el Centro IT para la Ciencia de Finlandia. El desarrollo de la plataforma se hizo en el CERN. Finlandia ha sido escogida por su cercanía con el centro de investigación, pues las escuelas de este país visitan las instalaciones asiduamente y el profesorado tiene una preparación notable en física de partículas.
Desde el CERN apuntan que uno de los objetivos de este programa piloto es dar facilidades a la gente para construir herramientas educativas con la información procedente del CMS, posibilitando así que los estudiantes de instituto puedan llevar a cabo algunos análisis reales.
Cómo acceder a los datos
El objetivo del CERN es que la información sea accesible para una audiencia más amplia. Para facilitar esta tarea es el motivo por el que ha contado con la experiencia del Centro IT para la Ciencia de Finlandia, que ha proporcionado aplicaciones para imitar el entorno de investigación a pequeña escala.
Al entrar en el portal Open Data del CERN lo primero que aparecen son dos categorías: `Educación´, a la izquierda, e `Investigación´, a la derecha. Al pinchar en el primero la información aparece más accesible. Se incluyen datos seleccionados cuidadosamente. Los datasets (paquetes de información) se pueden usar accediendo la imagen en forma de máquina virtual del entorno CMS u otras herramientas. Junto a cada dataset aparecen las instrucciones para usar la información. Los datos se puede visualizar directamente en la web, aunque también es posible descargar los archivos en formato CSV, para abrirlos en una tabla.
Acceder a los datos destinados a investigadores es más complejo. "El problema de estos paquetes de datos es que hay muchísima información. No es quizás la complejidad de la misma sino más bien el volumen. Para poder analizar grandes cantidades de datos se requiere una potencia bastante alta", señala García Morales. Lo primero es instalar la herramienta de código abierto VirtualBox para ejecutar máquinas virtuales. Eso sí, la última versión cuya compatibilidad se ha comprobado con la máquina virtual del CERN es la 4.3.14, que se puede descargar aquí. A continuación hay que descargar la máquina virtual del experimento CMS desde aquí.
VirtualBox importa la imagen del entorno CMS, que se ejecuta al lanzar la máquina virtual. En la interfaz gráfica de usuario aparecerá el entorno CMS y ahora toca comprobar que todo se ha instalado correctamente. En la web del CERN están las instrucciones para hacerlo.
A la hora de navegar en la sección `Investigación´ del portal Open Data, la información está agrupada en paquetes o AOD (Analysis Object Data). Cada uno de estos paquetes tiene un tamaño de varios GB o TB, con lo que se necesitan sistemas con gran capacidad de almacenamiento para descargarlos. Dentro de un AOD se pueden encontrar índices además de los archivos correspondientes.